
Måling af øjenbevægelser kan lette læsningen for dig – mens du læser
En ny ph.d.-afhandling viser, at optagelser af læseres øjenbevægelser kan afsløre, om et enkelt ord volder problemer – blot få sekunder efter det er blevet læst. Det betyder, at computeren nu kan tilbyde at oversætte svære ord eller foreslå en lettere tekst, lige når læseren har brug for det. Den nye teknologi kan få stor betydning i uddannelsessystemet, især fordi øjenbevægelser nu kan optages med helt almindelige mobiletelefoner og tablets.
Når vi læser en tekst, fikserer vores øjne mange gange på de ord og sætninger, som vi af en eller anden grund har svært ved at læse. Det kan man se, når man udstyrer en computer med den såkaldte eyetracking-teknologi, som optager vores øjnes bevægelser. Tidligere har sprogforskerne især brugt teknologien til at undersøge, hvad der sker i hovedet på os, når vi læser, for fx at kunne udvikle generelle modeller for, hvad der kan gøre tekster svære at læse. Det kræver dog rigtig meget data og mange resurser at lave den slags undersøgelser, fordi man skal undersøge en repræsentativ gruppe af forskellige typer ord med så mange læsere som muligt for at kunne sige noget generelt om, hvordan en bestemt type af ord kan påvirke læsere i almindelighed.
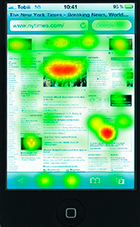
En iPhone med eyetracking-software installeret.
Ph.d.-studerende Sigrid Klerke er gået en helt anden vej: i stedet for at forsøge at lave en generel model, som skal fungere for mange mennesker og mange typer tekster, har hun udviklet en model, der er skræddersyet til at give et øjebliksbillede af en enkelt læser. Modellen baserer sig på, hvad der sker med den enkelte læsers øjne, lige i det øjeblik han eller hun læser en vilkårlig tekst:
- Mit system kan på baggrund af data opsamlet på få sekunder af eyetrackeren vurdere, om det ord, du kigger på lige nu og her, er et ord, du oplever som svært. Den oplysning ville kunne bruges til fx automatisk at foreslå en forklarende tekst eller en oversættelse. Systemet har altså lært at registrere, når du fikserer på teksten i et karakteristisk mønster, som vi ikke kunne have beskrevet på forhånd, forklarer Sigrid Klerke, som netop har færdiggjort afhandlingen Glimpsed - improving natural language processing with gaze data om, hvordan øjenbevægelsesdata kan bruges til at forbedre fx maskinoversættelse og automatisk tekstforenkling.
Resursebesparende teknologi
I forhold til andre typer af sprogteknologiske systemer har Sigrid Klerkes den fordel, at det ikke er afhængigt af, at nogle bearbejder de tekster, som systemet skal arbejde med.
- Inden for mit felt, sprogteknologien, bruges der overraskende mange resurser på at få sprogeksperter til at bearbejde tekster som en vigtig del af processen med at udvikle teknologierne – det kan fx være at forsyne ordene i en tekst med oplysninger om, hvilke ordklasser de tilhører, eller hvilke ord der kan udelades eller forenkles. Men læsernes øjenbevægelser kan jo betragtes som en slags bearbejdning in real time, som indeholder meget information, som vi kun lige er begyndt at regne ud, hvordan vi kan bruge – men det er meget hurtigere at få nogen til at læse en tekst end at få en ekspert til at analysere den samme tekst sprogligt. Det, vi gør med øjnene, er nemlig på ingen måde tilfældigt, siger Sigrid Klerke og uddyber:
- Uanset hvilken tekst det handler om, vil systemet kunne give et bud på, hvor svær læseren synes, at teksten er. Systemet behøver faktisk slet ikke at forholde sig til, hvilke ord teksten indeholder, men kun til den feedback, det får fra læserens øjenbevægelser. På den måde slipper vi både for at vente på, at vi kan betale eksperter for at bearbejde teksterne og for at være afhængige af overhovedet at kunne udvikle tilstrækkeligt præcise modeller for, hvad der afgør teksters sværhedsgrad. Vi udnytter i stedet alle de data, som vi får forærende, mens folk sidder og læser, til løbende at lette læsningen. Det er der, så vidt jeg ved, ingen, der har gjort før.
Læringssoftware og Google Translate
Et eyetracking-baseret læseunderstøttende system som det, Sigrid Klerke har gjort muligt, vil være noget, kommercielle spillere hurtigt ville kunne finde anvendelse for. Men også i uddannelsessystemet vil der være oplagte anvendelsesmuligheder:
- Eftersom eyetracking nu kan indbygges i mobiltelefoner og tablets, vil det ikke kræve særlig meget at integrere den her type software, som kan hjælpe eleverne, mens de sidder og læser – det kan fx være noget med at få justeret sværhedsgraden i en tekst eller at foreslå tekster, der indeholder en særlig type ord, som eleven har vanskeligheder ved og derfor har brug for at øve, foreslår Sigrid Klerke.
- Når Google og andre via mobiltelefoner og tablets også begynder at få adgang til brugernes øjenbevægelser, vil det være oplagt for dem at bruge feedbacken til at forbedre deres systemer: Man kan forestille sig, at hvis tilstrækkelig mange danskere fx fikserer påfaldende på det samme ord i en oversættelse, som Google Translate har lavet fra et fremmedsprog til dansk, kunne den information indgå automatisk i deres oversættelsessystemer som et tegn på, at der kunne være noget galt med oversættelsen af det ord. Google har så mange brugere, at de kan få afsindig meget anvendelig data på den måde.
Sigrid Klerke mener også, at der kan være juridisk interesse i software, som via øjenbevægelser kan dokumentere, at folk rent faktisk har læst dokumenter, som de er forpligtet til at læse i forbindelse med en ansættelse eller lignende processer.
Kontakt
Ph.d. Sigrid Klerke
Center for Sprogteknologi
Mail: skl@hum.ku.dk
Mobil: 60 64 43 31
Emner
Kontakt
Ph.d. Sigrid Klerke
Center for Sprogteknologi
Mail: skl@hum.ku.dk
Mobil: 60 64 43 31
Kommunikationsmedarbejder Carsten Munk Hansen
Det Humanistiske Fakultet
Mail: carstenhansen@hum.ku.dk
Mobil: 28 75 80 23
Om afhandlingen
Sigrid Klerkes ph.d.-afhandling består af fire forskellige studier, hvoraf tre allerede er blevet præsenteret på internationale konferencer og udgivet som artikler. De undersøger forskellige metoder til at bruge øjenbevægelsesdata til at forbedre sprogteknologiske værktøjer som maskinoversættelse og automatisk tekstforenkling.
I forbindelse med projektet er der blevet indsamlet data fra i alt 69 forsøgspersoner, i eyetracking-laboratorier på Københavns Universitet og University of Melbourne i Australien.